Grupo 6 - Integrantes:
-Alvarado Veintimilla Josue
-Guarquila Rosero Lissette
-Mera Sanchez Noemi
-Mina LunaNahomi
-Muñoz Miño Birmania
Ejercicio del
Libro Levin 11-30.
El gerente de una línea de ensamble de una plana manufacturera de relojes decidió estudiar de qué manera las diferentes velocidades de la banda transportadora afectan la tasa de unidades defectuosas producidas en un turno de ocho horas. Para ello, corrió la banda a cuatro velocidades distintas en cinco turnos de ocho horas cada uno y registró el número de unidades defectuosas encontradas al final de cada turno.
Los resultados del estudio son los siguientes:
a) Calcule el número medio de unidades defectuosas, x, para cada velocidad; luego determine la media, Gx.
b) Utilizando la ecuación 11-6, estime la varianza de la población (la varianza entre columnas).
c) Calcule el cociente F. al nivel 0.05 de significancia, ¿las cuatro velocidades de la banda transportadora producen la misma tasa media de relojes defectuosos por turno?
HIPÓTESIS:
RESOLUCIÓN:
a) 1. Para calcular la media de cada unidad defectuosa procedemos a determinar n (tamaño de la muestra) por cada unidad de medición así determinamos;
n=5.
2. Luego se suman los datos de las muestras de cada unidad de medición (velocidades) (37+35+38...); así:
3. Al tener la sumatoria total procedemos a dividir el resultado por
n -->(tamaño de la muestra) ya antes determinado:
4. Obtenemos el resultado que es la media por cada unidad de medición (muestras):
5. Procedemos a encontrar la Gran media (
Gx), sumando todos los datos de cada unidad de medida siendo esta:
6. Se procede a dividir por el total de datos que son 20, se determina por la suma de todas las muestras de cada unidad de medida:
7. Obtenemos entonces la Gran media:
b) Estime la varianza de la población (la varianza entre columnas):
Se determina en la tabla
n (tamaño de la muestra);
x (media);
Gx (Gran media);
^2 (elevado al cuadrado).
1. Se determina la cantidad de
n que tenemos por cada unidad de medición; igual sucede con la
x (media) y
Gx (Gran media) según correspondan.
2. Se procede a aplicar la ecuación;

ob
teniendo:
3. Se realiza una sumatoria total de (37,81 + 25,31 + 15,31 + 25,31); Siendo el resultado la
primera estimación de la varianza:
4. Dada la fórmula
; se procede a realizar, cambiando las letras por los datos obtenidos.
Entonces 34,58 es la varianza entre columnas.
c) Calcule el cociente F. al nivel 0.05 de significancia
α = 0.05
1. Calculamos los grados de libertad del númerador y el denominador.
Determinamos que:
k = número de muestras.
n = tamaño de la muestra.
gl - númerador: k - 1 ----> 4 - 1 = 3.
gl - denominador: n - 1 ----> 20 - 1 = 19
(Tabla) F = 5.01
TABLA ANOVA
1. Para realizar la tabla anova se procede hacer la tabla de errores y de suma total.
1.1 Se resta el tamaño de cada muestra por la Gx, ejemplo: (37-33,25); (35-33,25); ...
1.2 Se eleva los resultados dados al cuadrado y se obtiene:
1.3 Se suman todos los datos y se obtiene el total:
1.4 Se procede a realizar la tabla de errores; se resta el tamaño de cada muestra con la media de cada nivel de medición; así (37-36); (35-36); (38-36)...:
1.5 Luego, igual que en la anterior tabla se eleva todo al cuadrado y se realiza la sumatoria total.
1.6 Se reúnen los datos en la tabla ANOVA; obteniendo:
La media cuadrática es la suma de cuadrados de los tratamiento y errores divididos para sus respectivo grados de libertad; así: (103,75/3).
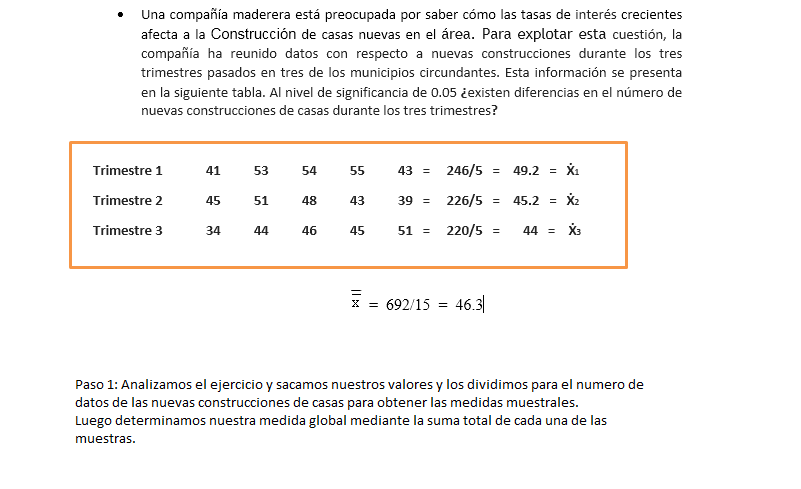























 de cada columna y lo realizamos sumando los valores de cada columna y dividiendo para n cantidades y demostramos los resultados a continuación:
de cada columna y lo realizamos sumando los valores de cada columna y dividiendo para n cantidades y demostramos los resultados a continuación:



























